Overview
This page provides an overview of the core concepts of LayeredRL.
Core Concepts
In reinforcement learning (RL), an agent interacts with an environment by choosing which action to take in each time step. The environment returns an observation, a reward, and indicates whether the episode ended. The objective of an RL agent is to act in a way that maximizes the cumulative expected reward over time. To distinguish advantageous from less advantageous actions, an agent has to assign credit to them. This becomes increasingly hard with longer problem horizons as it is not immediately clear how a long sequence of actions influences the rewards observed later.
Hierarchical reinforcement learning (HRL) tackles the problem of long-term credit assignment by decomposing complex tasks into simpler subtasks, allowing agents to learn and plan at multiple levels of abstraction. This strategy is inspired by how humans solve complex tasks: Instead of planning each small step after another, we first form a high-level plan which we then execute with more low-level skills. For example, think about the overwhelming task of cleaning your flat. You might first consciously make a rough plan (based on its current state) to split it up into vacuuming the floor, washing the dishes, and cleaning the bathroom. Once this plan is established, executing the first part – vacuuming – can feel more automatic and straight forward as you just have to invoke a skill you have trained many times before.
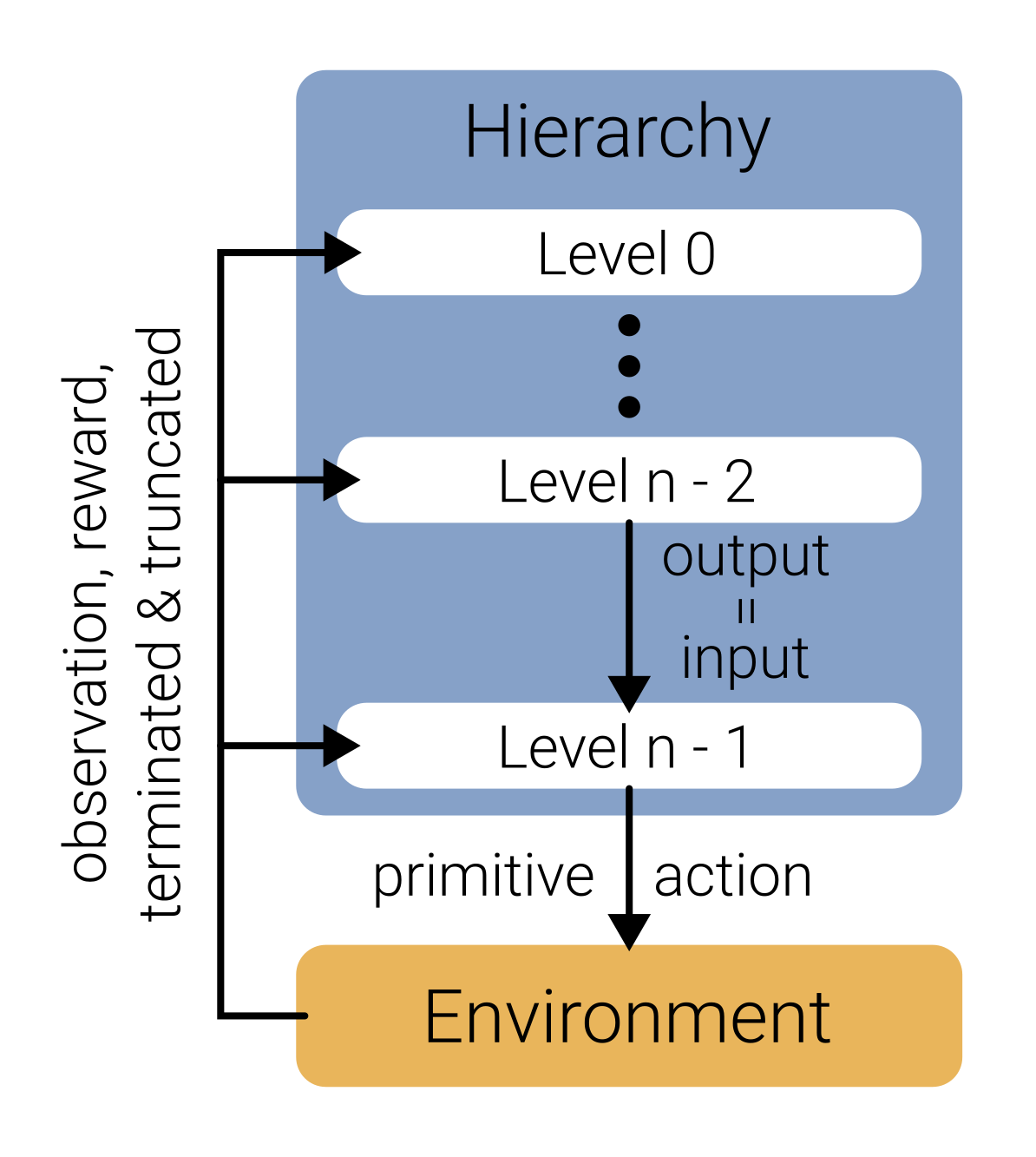
LayeredRL is designed to make this hierarchical approach practical and flexible. It takes the idea of tackling complex problems with multiple levels of abstraction and distills it into a modular HRL framework. A LayeredRL agent is structured as a hierarchy consisting of multiple levels. Each level sees the environment observation and the output of the level above. Levels higher up in the hierarchy operate on a coarser level of abstraction. While the lowest level is active at every environment time step (as it outputs the primitive action that is passed to the environment), the level above may be invoked less frequently. Hence, temporal abstraction increases when ascending the hierarchy. Similarly, the output (or action) of a higher level can correspond to more abstract concepts like subgoals or skill vectors in contrast to the primitive actions on the lowest level (e.g. joint torques). Finally, higher levels may only see certain aspects of the observation which are essential for forming a high-level plan (information hiding, e.g., a high-level planner may only see x-y position of a robot, not its joint angles).
Levels
The main role of a level is to
generate an action (or output) based on (i) an environment observation, and (ii) the output of the level above (if there is one),
to process the resulting (semi-MDP) transition once control is returned to the level from the level below (or the environment in case of the lowest level),
and to learn from these transitions.
Action generation in a level can be implemented by running a policy or a planning algorithm (or a combination of both in the case of TD-MPC2). Levels are modular building blocks for hierarchies. Not all levels can be easily combined though as the interface between them has to be well-defined. See Levels for more information.
Currently, the following levels are available:
Supported levels |
Type |
|---|---|
Model-based RL |
|
Model-free RL |
|
Skill (TD-MPC2 version) |
|
Skill |
|
Planner |
The Hierarchy
The hierarchy is responsible for integrating levels into a learning agent. This involves:
Initializing models and buffers in each level such that output and input of adjacent levels match
Traversing the hierarchy from top to bottom, to generate a primitive action that can be passed to the environment (forward pass)
Registering experience with each level once the environment transitioned into the next state, starting with the lowest level and moving up the hierarchy when control is returned to a parent level (backward pass)
This requires keeping track of which level is active in each instance at the moment (e.g., is a skill still being executed or a new one chosen?). Since higher levels usually obtain control only occasionally, they see transitions that span multiple environment time steps. For more information on hierarchies see Hierarchies.
Getting Started
Now that you understand the architecture, here’s how to proceed:
Installation: Installation
Quickstart: Quickstart - Build your first hierarchy
Examples: Examples - Working code examples
User Guides: Deep dives into Hierarchies, Levels, etc.
API Reference: Hierarchies API - Full API documentation
Key Takeaways
Note
Core Ideas to Remember:
Levels are modular RL, planning or skill learning algorithms you can stack
Hierarchies orchestrate multiple levels seamlessly
Fully vectorized - scales to parallel environments
Ready to build hierarchies? Start with the Quickstart guide!